Ceph
A Ceph Storage Cluster requires at least one Ceph Monitor, Ceph Manager, and Ceph OSD (Object Storage Daemon). The Ceph Metadata Server is also required when running Ceph Filesystem clients.
- Monitors: A Ceph Monitor (ceph-mon) maintains maps of the cluster state, including the monitor map, manager map, the OSD map, and the CRUSH map. These maps are critical cluster state required for Ceph daemons to coordinate with each other. Monitors are also responsible for managing authentication between daemons and clients. At least three monitors are normally required for redundancy and high availability.
- Managers: A Ceph Manager daemon (ceph-mgr) is responsible for keeping track of runtime metrics and the current state of the Ceph cluster, including storage utilization, current performance metrics, and system load. The Ceph Manager daemons also host python-based plugins to manage and expose Ceph cluster information, including a web-based dashboard and REST API. At least two managers are normally required for high availability.
- Ceph OSDs: A Ceph OSD (object storage daemon, ceph-osd) stores data, handles data replication, recovery, rebalancing, and provides some monitoring information to Ceph Monitors and Managers by checking other Ceph OSD Daemons for a heartbeat. At least 3 Ceph OSDs are normally required for redundancy and high availability.
- MDSs: A Ceph Metadata Server (MDS, ceph-mds) stores metadata on behalf of the Ceph Filesystem (i.e., Ceph Block Devices and Ceph Object Storage do not use MDS). Ceph Metadata Servers allow POSIX file system users to execute basic commands (like ls, find, etc.) without placing an enormous burden on the Ceph Storage Cluster.
Ceph stores data as objects within logical storage pools. Using the CRUSH algorithm, Ceph calculates which placement group should contain the object, and further calculates which Ceph OSD Daemon should store the placement group. The CRUSH algorithm enables the Ceph Storage Cluster to scale, rebalance, and recover dynamically.
Architecture
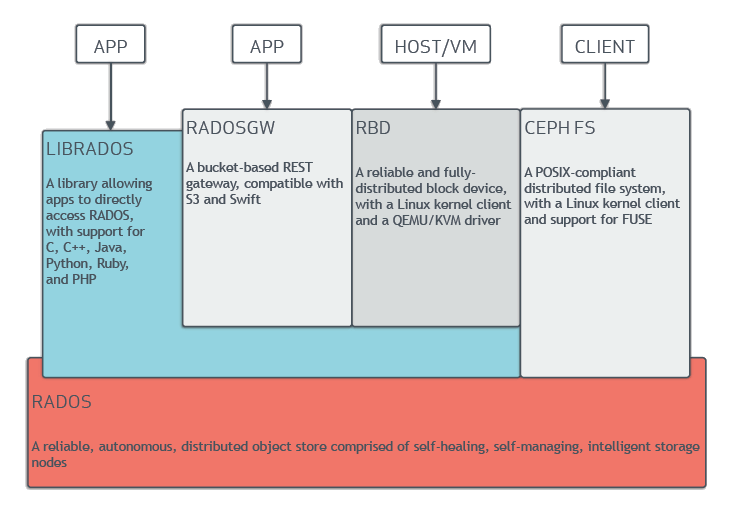
Ceph uniquely delivers object, block, and file storage in one unified system. Ceph is highly reliable, easy to manage, and free. The power of Ceph can transform your company’s IT infrastructure and your ability to manage vast amounts of data. Ceph delivers extraordinary scalability–thousands of clients accessing petabytes to exabytes of data. A Ceph Node leverages commodity hardware and intelligent daemons, and a Ceph Storage Cluster accommodates large numbers of nodes, which communicate with each other to replicate and redistribute data dynamically.
 (°0°)
(°0°)
- Ceph cluster has POOLS , pools are the logical group for storing objects .These pools are made up of PG ( Placement Groups ). At the time of pool creation we have to provide number of placement groups that the pool is going to contain , number of object replicas ( usually takes default value , if other not specified )
- PG ( Placement Group ): Ceph cluster links objects –> PG . These PG containing objects are spread across multiple OSD and improves reliability.
- Object : Object is the smallest unit of data storage in ceph cluster. Objects are mapped to PG , and these Objects / their copies always spreaded on different OSD.
Objects -> Pool -> Placement Groups -> OSDs
Ceph storage cluster can have more than one Pools
Each pool SHOULD have multiple Placement Groups . More the PG , better your cluster performance , more reliable your setup would be.
A PG contains multiple Objects.
A PG is spreaded on multiple OSD , i.e Objects are spreaded across OSD. The first OSD mapped to PG will be its primary OSD and the other ODS's of same PG will be its secondary OSD.
An Object can be mapped to exactly one PG
Many PG's can be mapped to ONE OSD
how the data is stored
Ceph uses CRUSH (controlled, scalable, decentralized placement of replicated data) algorithm for random and distributed data storage among the OSDs. Ceph doesn’t need two round-trips for data retrieval like HDFS or GFS, in which one trip is to the central lookup table to find the data location and the second trip is to the located data node. Every bit of data stored in Ceph OSDs is self-calculated using the CRUSH algorithm and stored independent of any other attribute. When a client requests data from Ceph, this CRUSH algorithm is used to find the exact location of all the requested blocks, and the data is transferred by the responsible OSD nodes.
As and when any OSD goes down, a new cluster map is generated in the background and the duplicate data of the crashed OSD is transferred to a new node based on results from the CRUSH algorithm.
workflow of retrieving data from ceph
refer
- components: monitors, managers, ceph osds, mds
- data –> RADOS –> Objects in ceph –> pool –> pg –> osd
- different data model retrieve
object --> RGW --> LIBRADOS-->RADOS --> objects in ceph ... block --> RBD --> LIBRADOS-->RADOS --> objects in ceph ... FILE --> cephfs --> LIBRADOS-->RADOS --> objects in ceph ..
Command
ceph -s Status summary
ceph df Disk useage overview, global and per pool
ceph health detail Details about health issues
ceph osd df tree Displays disk usage linked to the CRUSH tree, including weigths and variance
ceph osd pool ls {detail} List pools and optionally some details
ceph osd pool set {name} {param} {val} Set a pool parameter, e.g. size
ceph osd reweight {num} {wght} Temparorily override weight instead of 1 for this OSD
ceph osd reweight-by-utilization {percent} Ceph tries to balance disk usage evenly
ceph osd tree Lists hosts, their OSDs, up/down status, their weight, local reweight
CSI
refer
- PersistentVolume, status transfering is available–>bound–>released, has same recycle policy
- PersistentVolumeClaim, request for PV, pending–>bound
- StorageClass, pointing to ceph cluster by clusterid and pool
- VolumeAttachment, the mapping of
and - CSINode, csi plugin info
- VolumeHandle
 (°0°)
(°0°)
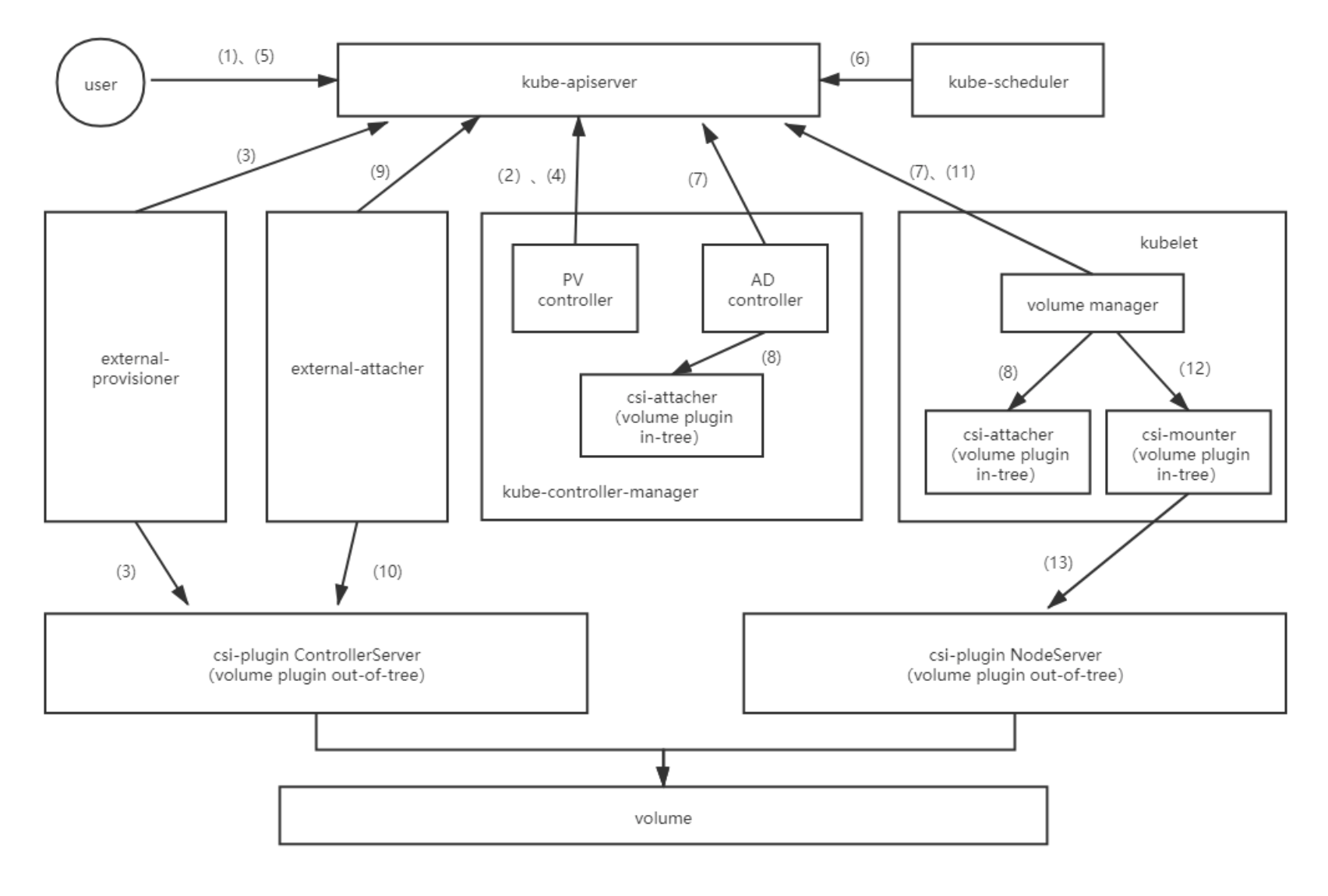
(1)用户创建pvc; (2)PV controller watch到pvc的创建,寻找合适的pv与之绑定。当寻找不到合适的pv时,将更新pvc对象,添加annotation:volume.beta.kubernetes.io/storage-provisioner,让external-provisioner组件开始开始创建存储与pv对象的操作。 (3)external-provisioner组件watch到pvc的创建,判断annotation:volume.beta.kubernetes.io/storage-provisioner的值,即判断是否是自己来负责做创建操作,是则调用csi-plugin ControllerServer来创建存储,并创建pv对象。 (4)PV controller watch到pvc,寻找合适的pv(上一步中创建)与之绑定。 (5)用户创建挂载pvc的pod; (6)kube-scheduler watch到pod的创建,为其寻找合适的node调度。 (7)(8)pod调度完成后,AD controller/volume manager watch到pod声明的volume没有进行attach操作,将调用csi-attacher来做attach操作(实际上只是创建volumeAttachement对象)。 (9)external-attacher组件watch到volumeAttachment对象的新建,调用csi-plugin进行attach操作(如果volume plugin是ceph-csi,external-attacher组件watch到volumeAttachment对象的新建后,只是修改该对象的状态属性,不会做attach操作,真正的attach操作由kubelet中的volume manager调用volume plugin ceph-csi来完成)。 (10)csi-plugin ControllerServer进行attach操作,将volume挂载到pod所在node节点,成为如/dev/vdb的设备。 (11)(12)attach操作完成后,volume manager watch到pod声明的volume没有进行mount操作,将调用csi-mounter来做mount操作。 (13)csi-mounter调用csi-plugin NodeServer进行mount操作,将node节点上的第(10)步得到的/dev/vdb设备挂载到指定目录。
setting up ceph
- ceph-ansible
- create ceph pool
- create client user
- deploy ceph-csi
- csi-configmap
- create new secret in k8s
- RBAC
- CSI sidecar csi-rbdplugin-provisioner.yaml, csi-rbdplugin.yaml
- CSI driver
- create Storageclass
- verify ceph-csi
monitoring osds and pgs
refer