RAG
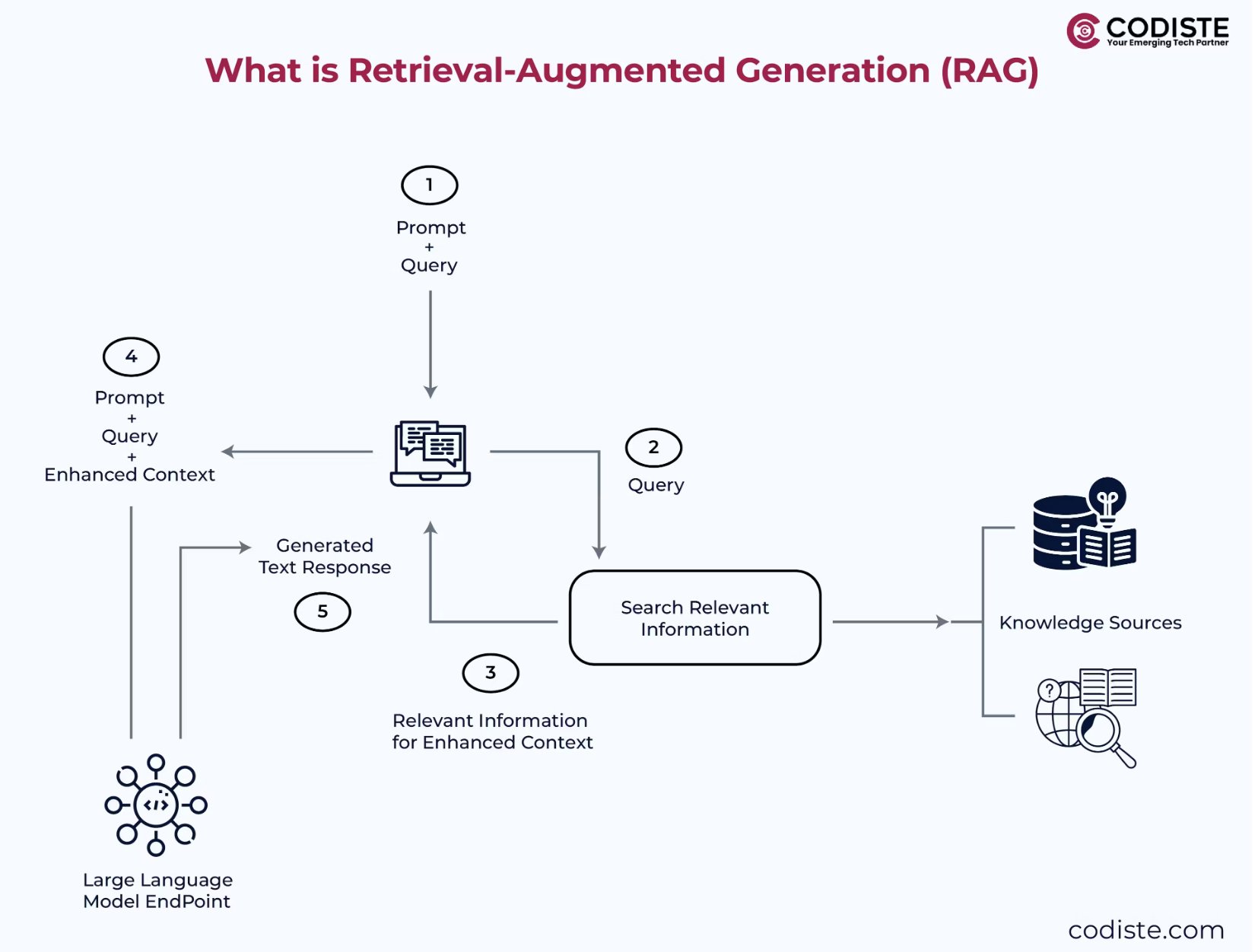
Retrieval-augmented generation (RAG) is where the outputs of large language models are optimized to reference an authoritative knowledge base outside of its training data sources before generating a response. Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters that generate original output for tasks like answering questions, language translation, and completing sentences.
RAG extends the already powerful capabilities of LLMs to specific domains or an organization’s internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output, so it remains relevant, accurate, and helpful in various contexts.
Additionally, RAG enhances retrieval and response generation by employing dynamic strategies that consider context, conversation history, and real-time observations, improving efficiency and effectiveness.
 (°0°)
(°0°)