Reinforcement-learning-from-human-feedback
Reinforcement learning from human feedback (RLHF) fine-tunes a pre-trained LLM by incorporating human feedback as a reward function during the training process. Human evaluators assess the model’s outputs, ranking them based on quality, relevance, or alignment with specific goals, and this feedback trains a reward model.
RLHF training optimizes the LLM to maximize the rewards predicted by this model, effectively adjusting its behavior to better align with human preferences.
 (°0°)
(°0°)
The RLHF process is iterative and feedback-driven, refining the LLM’s outputs through a structured sequence of steps. Here’s how it works.
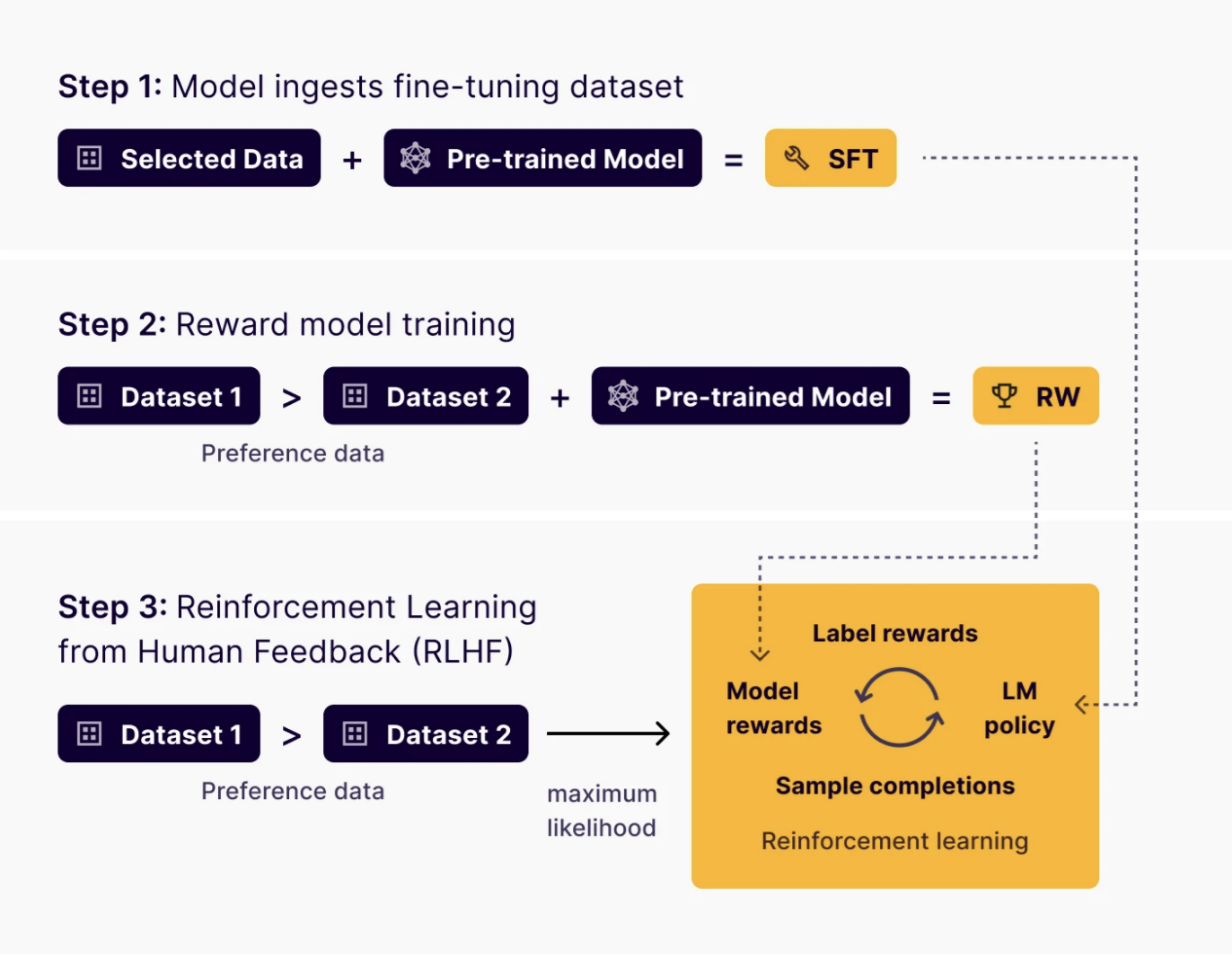
Step 1: Initial supervised fine-tuning
The RLHF process usually starts with SFT. In the initial phase, AI teams train a “policy” model, which serves as the LLM for further refinement through RLHF. This provides the model with a solid starting point for both general language understanding and some task-relevant skills.
Step 2: Human guidance collection
Human evaluators review the policy model generated text, providing feedback by ranking them, giving detailed critiques, or labeling them as either ‘good’ or ‘bad’. This human input is important for constructing a reward model that can understand human preferences.
Step 3: Reward model training
A separate model, the reward model, is then trained to predict human preferences. The training data for the reward model consists of the model-generated responses paired with the human rankings or ratings. The reward model aims to learn to assign a numerical score to each response, such that responses that humans preferred receive higher reward scores and less preferred responses receive lower scores.
Using a reward model to provide reinforcement can also be referred to as RLAIF, or reinforcement learning with AI feedback.
Step 4: Fine-tune with reinforcement learning
After training the reward model on human preferences, the final RLHF step applies reinforcement learning to further fine-tune the policy model. This involves:
Policy model response generation: The policy model generates new responses.
Reward scoring or reward signal by the reward model: The trained reward model evaluates these generated responses and assigns a reward score to each.
Reinforcement learning optimization: A reinforcement learning algorithm, such as Proximal Policy Optimization (PPO), updates the policy model’s parameters. The algorithm’s objective is to adjust the policy model to maximize the reward scores predicted by the reward model. Essentially, the policy model is “reinforced” to produce responses that the reward model would consider high quality.
Iteration and refinement: RLHF is often an iterative process. Human feedback is collected on its new, improved responses as the policy model improves. The reward model might be further refined, and the policy model might be fine-tuned again using reinforcement learning. This iterative feedback loop is key to continuous improvement and alignment with evolving human preferences.
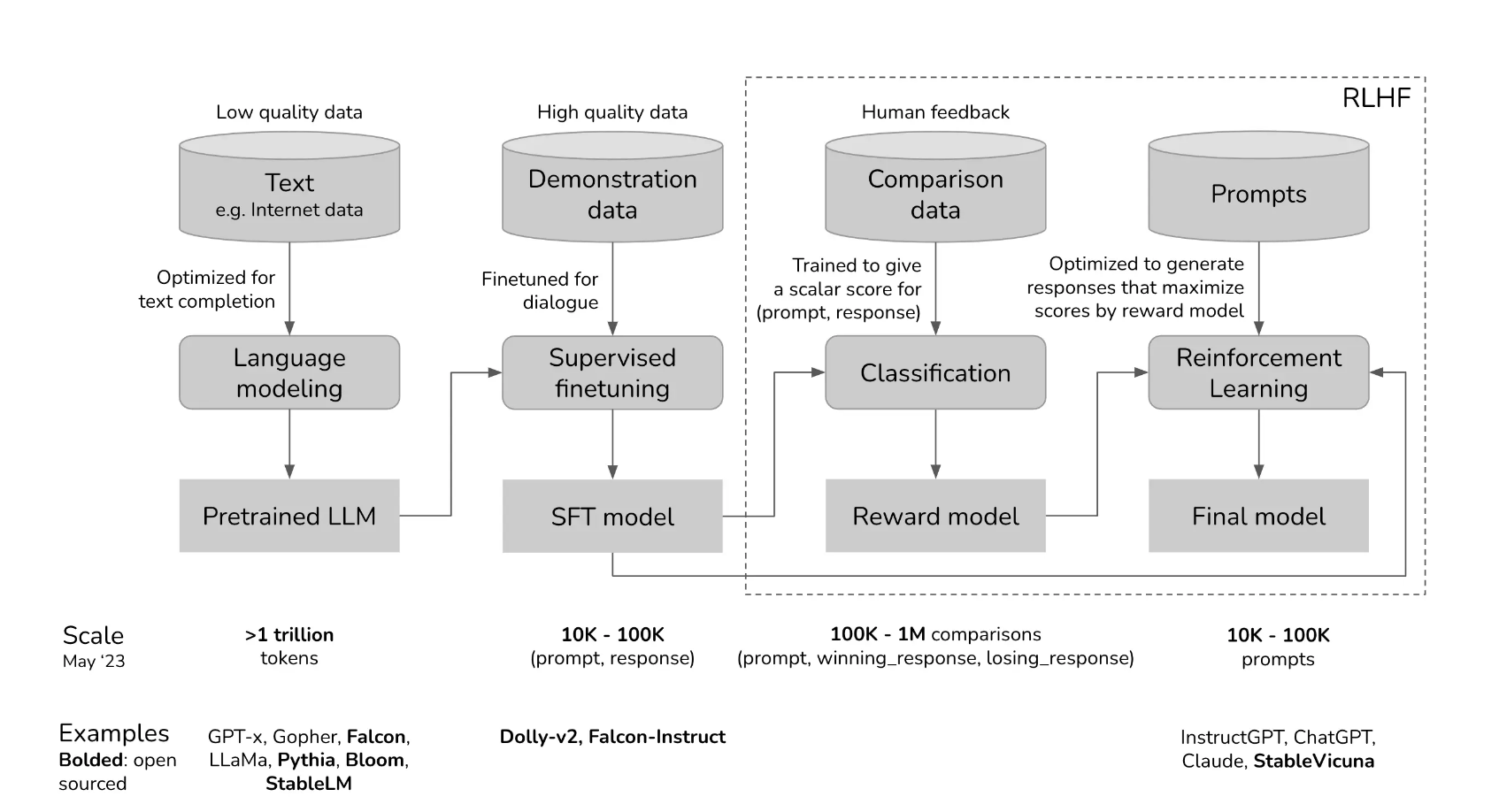
Stages
 (°0°)
(°0°)
Pre-Training
Instruction-Tuning
RLHF
Parameters
temperature
top-k
top-p
max length
seed