Cruise control
Cruise-control is the first of its kind to fully automate the dynamic workload rebalance and self-healing of a kafka cluster. It provides great value to Kafka users by simplifying the operation of Kafka clusters.
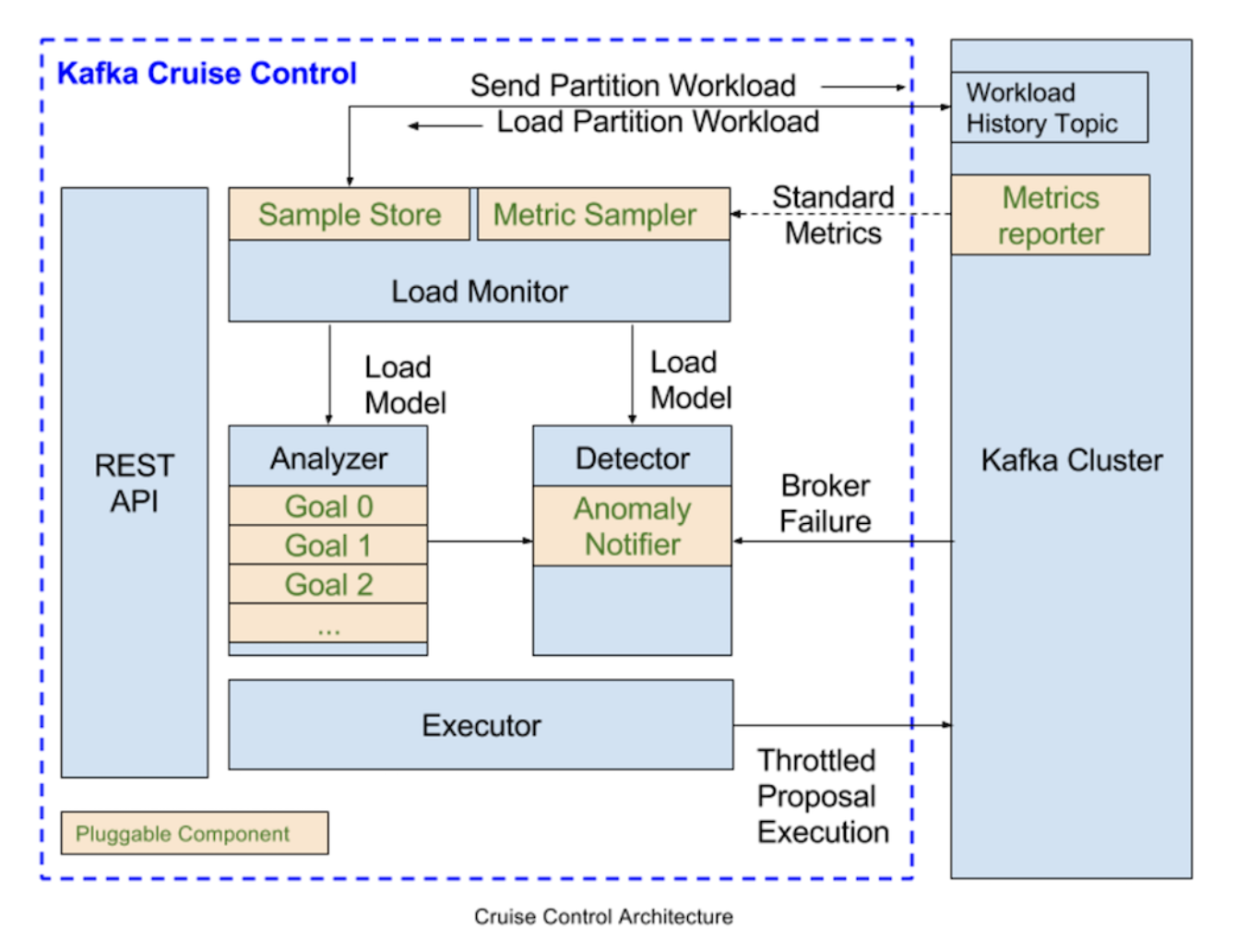
Architecture
refer
 (°0°)
(°0°)
-
REST API
Cruise Control provides a REST API to allow users to interact with it. The REST API supports querying the workload and optimization proposals of the Kafka cluster, as well as triggering admin operations. -
Load Monitor
The Load Monitor collects standard Kafka metrics from the cluster and derives per partition resource metrics that are not directly available (e.g., it estimates CPU utilization on a per-partition basis). It then generates a cluster workload model that accurately captures cluster resource utilization, which includes disk utilization, CPU utilization, bytes-in rate, and bytes-out rate, at replica-granularity. It then feeds the cluster model into the detector and analyzer. -
Analyzer
The Analyzer is the “brain” of Cruise Control. It uses a heuristic method to generate optimization proposals based on the user-provided optimization goals and the cluster workload model from the Load Monitor.
The optimization goals have priorities based on the user configuration. A higher priority goal is more likely to be met than a low-priority goal. The optimization of a low-priority goal cannot cause violation of the high priority goals.
Cruise Control also allows for specifying hard goals and soft goals. A hard goal is one that must be satisfied (e.g., replica placement must be rack-aware). Soft goals, on the other hand, may be left unmet if doing so makes it possible to satisfy all the hard goals. The optimization would fail if the optimized results violate a hard goal. Usually, the hard goals will have a higher priority than the soft goals. We have implemented the following hard and soft goals so far: -
Hard Goals
Replica placement must be rack-aware. The replicas of the same partition are put on different racks so that when a rack is down, there will be at most one replica lost for any partition. This helps control the failure boundary and makes Kafka more robust.
Broker resource utilization must be within pre-defined thresholds.
Network utilization must not be allowed to go beyond a pre-defined capacity, even when all replicas on the broker become leaders. In this case, all the consumer traffic will be redirected to that broker, which will result in higher network utilization than usual. -
Soft Goals
Attempt to achieve uniform resource utilization across all brokers.
Attempt to achieve uniform bytes-in rate of leader partitions (i.e. the bytes-in rate from the clients instead of replication) across brokers.
Attempt to evenly distribute partitions of a specific topic across all brokers.
Attempt to evenly distribute replicas (globally) across all brokers.
At a high level, the goal optimization logic is as follows:
-
Anomaly detector
The anomaly detector identifies two types of anomalies:
Broker failures: i.e., a non-empty broker leaves a cluster, which results in under-replicated partitions. Since this can happen during normal cluster bounces as well, the anomaly detector provides a configurable grace period before it triggers the notifier and fixes the cluster.
Goal violations: i.e., an optimization goal is violated. If self-healing is enabled, Cruise Control will proactively attempt to address the goal violation by automatically analyzing the workload, and executing optimization proposals. -
Executor
The executor is responsible for carrying out the optimization proposals from the analyzer. Rebalancing a Kafka cluster usually involves partition reassignment. The executor ensures that the execution is resource-aware and does not overwhelm any broker. The partition reassignment could also be a long-running process—it may take days to finish in a large Kafka cluster. Sometimes, users may want to stop the ongoing partition reassignment. The executor is designed in a way that it is safe to interrupt when executing the proposals.
Features
-
Resource utilization tracking for brokers, topics, and partitions.
-
Query the current Kafka cluster state to see the online and offline partitions, in-sync and out-of-sync replicas, replicas under min.insync.replicas, online and offline logDirs, and distribution of replicas in the cluster.
-
Multi-goal rebalance proposal generation for:
Rack-awareness
Resource capacity violation checks (CPU, DISK, Network I/O)
Per-broker replica count violation check
Resource utilization balance (CPU, DISK, Network I/O)
Leader traffic distribution
Replica distribution for topics
Global replica distribution
Global leader replica distribution
Custom goals that you wrote and plugged in -
Anomaly detection, alerting, and self-healing for the Kafka cluster, including:
Goal violation
Broker failure detection
Metric anomaly detection
Disk failure detection (not available in kafka_0_11_and_1_0 branch)
Admin operations, including: -
Add brokers
Decommission brokers
Demote brokers
Rebalance the cluster
Fix offline replicas (not available in kafka_0_11_and_1_0 branch)
Perform preferred leader election (PLE)
Fix offline replicas
Frondend
refer
prefer goals
LeaderBytesInDistributionGoal - *Attempts to equalize the leader bytes in rate on each host
TopicReplicaDistributionGoal - *Attempts to maintain an even distribution of any topic's replicas across the cluster
ReplicaDistributionGoal - *Attempts to make all the brokers in a cluster have a similar number of replicas
PreferredLeaderElectionGoal - *Simply move the leaders to the first replica of each partition